
In anul 2011, Google lansa algoritmul Panda, cel care analiza site-urile si oprea procesul de ranking al acestora daca se constata ca exista continut de slaba calitate sau duplicat. Insa din 2016, Google a integrat acest algoritm in sistemul sau de rafinare a rezultatelor iar, de atunci, continutul duplicat a devenit problema pregnanta a detinatorilor de website-uri, mai ales ca acesta ruleaza in timp real. Specialistii considera ca din 2016 pana in prezent, cel putin 30% dintre website-urile worldwide au avut de suferit – circa 5% au trebuit refacute de la zero si 25% dintre ele au primit restrictii in ceea ce inseamna relevarea rezultatelor.
Dincolo de acest aspect, problema continutului duplicat a fost, dintotdeauna, principala preocupare a agentiilor de SEO, dobandind o valoare si mai mare in practicile aplicate onpage si offpage. Daca la prima vedere necunoscatorii considera ca nu este neaparat o problema, specialistii in optimizare SEO ii contrazic, intarind ideea ca nu trebuie neglijata aceasta problema, mai ales ca motoarelor de cautare le este greu le dea paginilor importanta pe care o merita.
Ce inseamna “continut duplicat” ?

Asa cum ne spune si numele, este vorba despre continutul postat pe paginile noastre care poate fi asemanator sau identic cu cel al altor site-uri, sau chiar cu propriile pagini de site. Continutul duplicat poate insemna acelasi continut in mai mai multe pagini din site sau/si acelasi continut cu alte site-uri. Insa, din toata aceasta strategie este uitat deseori aspectul cel mai important, cel pe care l-am enuntat mai devreme: pana sa ajungem prin site-urile noastre la utilizatori, acestea trebuie sa fie indexate pagina cu pagina de catre motoarele de cautare.
De la lansarea algoritmului Panda, website-urile care aplica aceasta tehnica de continut sunt penalizate extrem de rapid fiind, de asemenea, considerata tehnica de optimizare black hat.
De regula, problema continutului duplicat apare mai ales in cazul magazinelor online, unde varietatea mare de produse face aproape imposibila optimizarea SEO unica a paginilor, urmate indeaproape de site-urile de stiri, al caror continut este uploadat zilnic.
Tot in categoria continutului duplicat se incadreaza si textele copiate si postate pe alte pagini. Din pacate aici discutia este mai ampla, deoarece motoarele de cautare nu vor cauta pagina sursa ci o vor afisa ca rezultat de incredere pe cea cu relevanta cea mai mare. Aici sunt inclusi diversi parametri ce pot fi luati in calcul precum: vechimea site-ului, rata de respingere (bounce rate) sau traficul generat pe site.
Cum apare continutul duplicat ?

Indiferent cat de bine este optimizat website-ul, daca acesta contine duplicate din punct de vedere al textelor sau a structurii link-urilor, se impune, in primul rand, o analiza SEO amanuntita, apoi strategii de rezolvare a situatiei.
In principiu, cele mai mari probleme in ceea ce priveste continutul duplicat apar in cazul magazinelor online. Larga varietate de produse, impreuna cu descrierile impuse de producatori (ce se regasesc, la fel, pe mai multe site-uri), filtrele si optiunile legate de relevanta sunt cele mai importante aspecte de luat in considerare.
Pe scurt, continutul duplicat se remarca prin:
- domenii necanonice - faptul ca website-ul are functioneaza pe adrese de web distincte, precum http://domeniu.ro, http://www.domeniu.ro, https://domeniu.ro, https://www.domeniu.ro, fara ca acestea sa faca redirect 301 catre varianta preferata din Search Console
- implementarea incorecta a certificatului SSL - daca se foloseste aceasta criptare exista sanse sa existe copii ale site-ului pe versiunea care a fost securizata, adicat atat varianta htttp, cat si https
- continut dinamic - exista site-uri care atribuie parametrii url-ului pentru a controla continutul. Ca si cu ID-urile de sesiune, motoarele de cautare interpreteaza asta ca duplicate
- paginare – daca mai multe pagini web detin aceeasi descriere sau acelasi titlu apare din nou problema continutului duplicat
- pagina de produs are mai multe URL-uri – cauzate de aplicarea filtrelor sau selectarea anumitor categorii din site
- aplicarea filtrelor de pret sau de sortare (relevanta, pret mai mic, pret mai mare) genereaza continut duplicat sau asemenator celui static
- platforma genereaza si salveaza automat mai multe adrese URL, in timp ce o postare este alocata in mai multe sectiuni ale site-ului
- site-ul dispune de indexarea variantelor de URL cu parametrul AMP (Accelerated Mobile Pages)
- platforma genereaza si salveaza automat mai multe adrese URL, in timp ce o postare este alocata in mai multe sectiuni ale site-ului.
Indiferent de tipul website-ului, specialistii SEO recomanda unicitatea continutului. In cazul magazinelor online, situatia este mult mai grava cu cat numarul produselor este mai mare. Altfel spus, majoritatea detinatorilor de platforme de ecommerce pur si simplu copiaza descrierile de produse dintr-o baza pe care o impartasesc cu alti distribuitori, iar daca se adauga informatiile cu privire la produs in structura fotografiei, raportul de continut duplicat creste alarmant. In aceasta situatie, Google doar scaneaza pagina, dar este in dificultatea de a identifica subiectul, relatia acestuia dintre pagini si intregul website precum si de ce ar trebui sa fie relevanta in cautarile internautilor.
Este primordial ca macar cele mai importante sau vizitate pagini sa aiba continut unic, mai ales ca acelea sunt principalele care atrag trafic si conversii. Evident, in cazul magazinelor cu sute sau mii de produse este aproape imposibil sa creezi continut unicat pentru fiecare in parte, dar agentiile SEO vin cu o solutie salvatoare – ordonarea site-ului cat mai logic, astfel incat sa fie create descrieri unice pentru categorii si subcategorii.
De asemenea, specialistii in marketing online vin si cu o solutie la problema descrierilor tehnice ale producatorilor. Desi aceste informatii sunt utile si creeaza o experienta pozitiva pentru clienti, Google identifica si acest tip de continut, care poate fi urmat de o penalizare. In aceasta situatie este indicata parerile si experientele vizitatorilor, iar caracteristicile tehnice ale produselor sa fie integrate in Social Media.
Cum afecteaza continutul duplicat evolutia SEO a website-ului ?
Odata mentionat ce inseamna “duplicat”, este timpul sa aflam cum acesta tehnica iti afecteaza negativ evolutia. In primul rand, un continut duplicat (text, URL) il va face pe Google sa nu inteleaga ce versiune trebuie sa indexeze. In al doilea rand, Googlebot nu va sti carui URL sa ii aloce date metrice si carei versiuni sa ii ofere rank-ul pentru rezultatele cautarii.
Altfel spus, unele dintre cele mai importante impedimente in evolutia website-ului in motoarele de cautare sunt reprezentate de:
- paginile incorecte – altfel spus, cand pe pagini exista un continut duplicat sau usor asemanator, motoarele de cautare aleg ce pagina se indexeaza prima
- vizbilitatea scazuta – evident, principala problema cand exista continut duplicat este reprezentata de vizibilitatea redusa a website-ului/paginii in principalele motoare de cautare
- indexare deficienta – practic, un motor de cautare cauta mai intai in paginile duplicate decat in cele care sunt cu adevarat importante. Astfel, daca proportia continutului duplicat este foarte mare, Google indexeaza o parte semnificativa a acestuia.
Cum verificam daca un website are sau nu continut duplicat !
Prima si cea mai indicata unealta oferita de Google pentru verificarea continutului duplicat este Google Search Console. Odata accesata platforma, cu un click pe Search Appearance → HTML Improvements se pot vedea mai multe informatii cu privire la situatia website-ului, exact ca in aceasta imagine:

De asemenea, cu un click pe Duplicate meta description sau Duplicate title tags, vor fi afisate si URL-urile care au titluri sau descrieri duplicate. Instrumentul va arata cantitatea de duplicate astfel incat sa poata fi revizuite.
O alta modalitate de a verifica continutul duplicat este reprezentata de cautarea anumitor produse, fraze sau texte in website, care indica daca titlurile si meta descrierile sunt sau nu duplicate. Desi presupune mai multa munca, ramane cea mai viabila solutie de a repera continutul duplicat si ponderea acestuia pe intreg website-ul.
Un raport complet privind situatia continutului duplicat al unui website este oferit si de Screaming Frog. Acesta este un program pe care specialistii in optimizarea SEO il utilizeaza frecvent pentru a verifica link-uri, imagini, meta-uri, heading-uri si alte erori. Practic, acesta actioneaza ca un spider, iar in cateva minute un raport complet este gata pentru a fi downloadat.
Eliminarea sau minimizarea efectelor continutului duplicat prin rel = Canonical este cea mai buna solutie ?
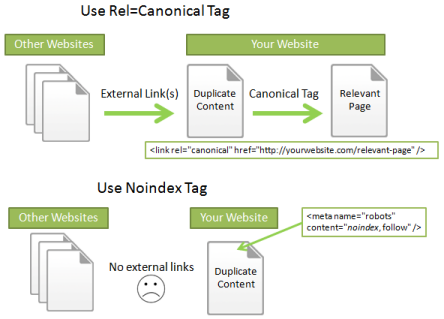
Tag-ul rel = canonical este un element tehnic de SEO care nu influenteaza in nicio masura experienta utilizatorului pe website, insa odata identificat de motoarele de cautare, acesta va prioritiza diferitele landing page-uri pentru indexare, crawling si ranking.
Altfel spus, tag-ul canonical ii specifica lui Google si altor motoare de cautare care este URL-ul sursa (respectiv pagina originala), astfel incat sa o ajute sa creasca in ranking. Motoarele de cautare folosesc acest tag pentru a combate duplicatele si a le permite paginilor originale sa se surclaseze asa numitelor “clone”. Spre exemplu, in cazul selectarii de prezentare a produselor sub forma de grid sau lista, Url-ul este dispus modificarilor, desi este acelasi continut in mai multe pagini. Astfel, pentru ca motoarele de cautare sa nu identifice doua URL-uri ca duplicat, specialistii SEO recurg la tag-ul Canonical, prin care se semnaleaza ca si restul paginilor fac parte din categoria sau subcategoria mama. Acesta este un exemplu de website ale caror pagini pot fi considerate duplicate, ca urmare a aplicarii filtrelor:
- http://www.site.ro/pagina-statica?&orderby=price
- http://www.site.ro/pagina-statica?&ordeby=name
- http://www.site.ro/pagina-statica?&orderway=desc
- http://www.site.ro/pagina-statica?&orderway=asc
Tag-ul rel = canonical a fost conceput tocmai pentru a aborda problema continutului duplicat, deci ramane cea mai buna solutie. Practic, la implementare se creeaza o linie de cod in sectiunea <head> a codului HTML a paginii.
Desi tag-ul canonical este cea mai buna optiune, mai exista si alte metode de a reduce continutul duplicat dintr-un website – prin redirect 301. Aceasta solutie poate fi abordata doar in cazul in care se face transferul continutului de pe o pagina pe alta, insa situatiile difera de la caz la caz. Mai multe informatii despre redirect 301 aici.
Canonicalizare si elementul rel = canonical

Tag-ul rel=canonical si procesul de canonicalizare sunt doar doua dintre actiunile de blocare a indexarii URL-urilor ce contin duplicat. De fapt, acestea doua conlucreaza in eliminarea duplicatelor si protejarea website-urilor de penalizarile lui Google, cum ar fi reducerea traficului si a vizibilitatii, precum si ranking-ul.
Astfel, se impune o scurta diferentiere intre cele doua, dupa cum urmeaza:
Canonicalizare – se impune in momentul in care un website genereaza mai multe URL-uri, cu acelasi continut. Practic, procesul de canonicalizare reprezinta alegerea celui mai bun URL din larga varietate cuprinsa in arhitectura, unde exista mai multe pagini cu acelasi continut.
De cealalta parte, tag-ul rel=canonical este un element de limbaj HTML, parte integranta in sectiunea de Header a oricarei pagini online. Cu ajutorul acestui tag, Google si alte motoare de cautare identifica continutul original si il claseaza superior fata de cel duplicat sau similar. Altfel spus, odata implementat acest tag, Google va returna rezultate catre versiunea de URL preferata. Aplicand rel=canonical de la un URL catre altul, motorul de cautare primeste informatia potrivit careia cele doua link-uri si-au unit fortele si prezinta un plus de incredere si autoritate in fata internautilor.
Rel = Canonical – cum se foloseste corect ?

In primul rand, totul sta in alegerea link-ului original, care sa contina informatie de calitate si relevanta pentru vizitatori. Astfel, dintre 2 sau mai multe link-uri considerate a fi asemanatoare, decizia trebuie cantarita in functie de: structura paginii, autoritatea, calitatea meta-urilor, precum si existenta recenziilor provenite de la clienti.
Concluzii
Continutul duplicat poate avea implicatii negative importante asupra campaniei SEO a unui site. Mai mult, nici utilizatorii nu vor fi foarte fericiti sa gaseasca acelasi continut pe care l-au mai vazut de n ori si pe alte site-uri. Din punctul nostru de vedere este mai bine sa avem continut mai putin dar original si relevant, decat sa avem mii de cuvinte copiate.
Pe langa faptul ca orice site cu URL-uri care afiseaza continut duplicat/asemenator este o tinta sigura urmarita de algoritmul core al motorului de cautare, pierderile suferite in materie de rank si trafic pot fi substantiale.
Asadar, evitati pe cat posibil continutul duplicat sau, daca nu puteti face acest lucru din diferite motive, incercati sa minimizati efectele negative folosing tagul canonical. Setat si implementat corect poate oferi rezultate eficiente!
Voi cum abordati problema continutului duplicat?